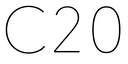PAGES
SEOUL
pages:jrnl:2022:2022...
ABOUT
NOW
JRNL
ESSY
RVIW
WIKI
검색
최근 바뀜
미디어 관리자
사이트맵
로그인
추적:
•
Q2023091301
•
The European: Chapter VII
•
제목
•
Neovim
•
2023-01-02
•
Bruckner Symphony No.9 (Knappertsbusch)
•
2022-09-26
2022-09-26
음악
사이먼 래틀
의
브람스
교향곡을 듣고 있다. 사이먼 래틀은 역시 다소 가볍고, 지휘자가 개입할 수 있는 수준의 리듬감에 천착하는 경향이 있다. 그래도 음악에 신경쓰지 않고 듣기에는 좋다.
Backlinks
Plugin Backlinks: 아무 것도 없습니다.
pages/jrnl/2022/2022-09-26.txt
· 마지막으로 수정됨:
2025/11/06 01:11
저자
127.0.0.1